
What role does HTTP play in facilitating the interaction between OData and online communication?
Understanding OData might seem unrelated, but it’s closely tied to HTTP, the backbone of the Internet. HTTP serves as the foundation for OData, making it a common language online.
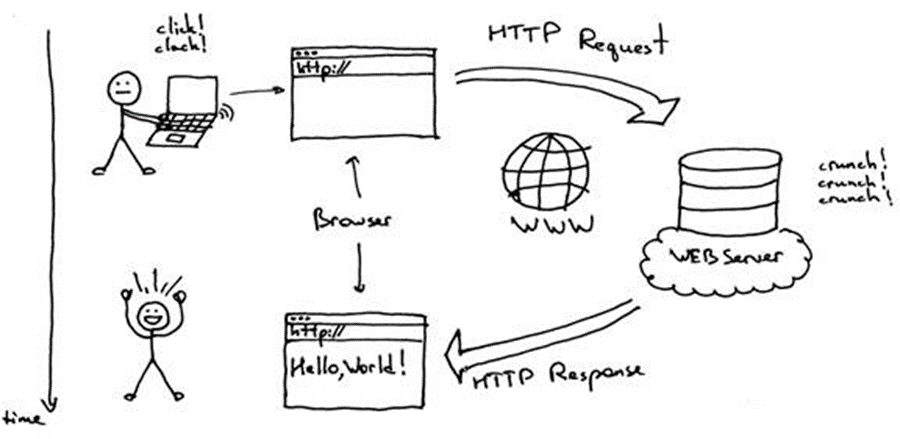
To access web content, you need a few basic tools: a web browser, the URL of the document you’re after, and a functioning web server hosting the document. Your web browser acts as your window to the web, interpreting HTML responses and constructing a Document Object Model (DOM) for you to interact with. By simply entering a URL, your browser sends an HTTP request to the web server, which responds with the requested document.
HTTP, short for Hyper Text Transfer Protocol, governs how browsers and web servers communicate. While HTTP handles the semantics of this interaction, the actual transfer of data packets occurs through TCP/IP protocols.
At the heart of this exchange is the web server, patiently awaiting client requests. It processes each request, formulates a response, and sends it back using HTTP. Notably, HTTP isn’t the only protocol in town, but it’s the most prevalent, catering to browsers and other HTTP-compatible software.
In formal terms, HTTP operates on a Client-Server architecture, employing a stateless request/response model. Each HTTP request stands alone; once the server responds, it forgets the request, maintaining no memory of prior interactions.
So, while OData and HTTP may seem distant, they’re actually deeply intertwined, thanks to HTTP’s foundational role in online communication.
Understanding the Contrast: URI vs URL
Remember when we talked about needing the URL to view a document in your browser? But what about using a URI instead? Let’s break down the difference between the two.
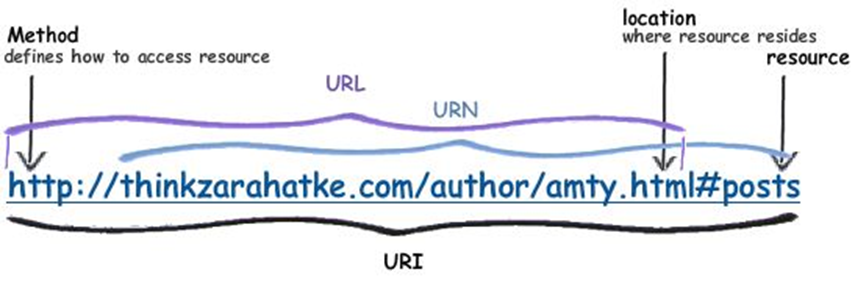
A URI, or Uniform Resource Identifier, is like a name or address that uniquely identifies a resource. It can be a name, a locator, or both.
Now, a URL, which stands for Uniform Resource Locator, is a specific type of URI. It not only uniquely identifies a resource but also provides the means to locate it. So, while all URLs are URIs, not all URIs are URLs.
Navigating Requests and Responses in HTTP
When you send an HTTP request, it’s like telling the server what you want to do with a particular resource. There are a couple of common methods for this:
GET: This method retrieves information from the server about the resource.
POST: With this method, you can send data to the server.
For instance, when you type something into Google’s search bar and hit enter, your browser quietly sends a GET request in the background. But if you’re logging into a website and submit your username and password, that triggers a POST request to the server.
Now, when the server responds to your request, it sends back both data and a status code. This code gives you insight into what happened with your request. If something went wrong, you’ll know why. For example, if you mistype a URL, your browser might return a response you weren’t expecting, along with a status code that tells you what went wrong.
These status codes are three-digit numbers with different meanings:
1xx: Informational – Your request has been received, and things are happening.
2xx: Success – Your request was understood and accepted.
3xx: Redirection – More steps are needed to complete your request.
4xx: Client Error – There’s a problem with your request, like bad syntax.
5xx: Server Error – The server couldn’t fulfill your request, even though it looked valid.
For instance, a status code of 400 means “Bad Request,” indicating that the server didn’t understand your request. OData works within this framework, allowing for the creation and use of RESTful APIs.
Exploring REST: Simplifying Inter-Machine Communication
REST, or Representational State Transfer, is a way for machines to communicate that’s both straightforward and lightweight. It offers an alternative to methods like RPC (Remote Procedure Calls) and Web Services.
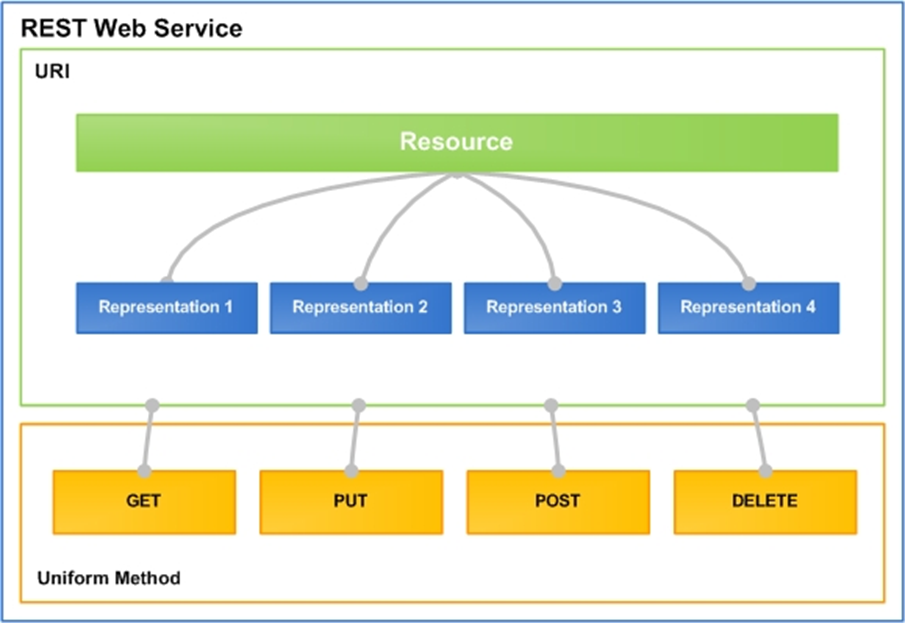
Unlike RPC or SOAP, which focus on actions, REST centers around resources. In SOAP, you might request specific data, but in REST, you identify resources using URIs and use HTTP verbs to decide what to do with them. It’s worth noting that multiple URIs can point to the same resource.
When we talk about representation in REST, we’re not talking about the actual resource itself, but rather a depiction of it. Representations show parts of the resource’s state, and they’re typically transferred between client and server in formats like JSON or XML. With this information, the client can interact with the resource on the server. For instance, if a “Person” is modeled as a resource, requesting contact information might return a representation with the person’s name, address, and phone details, formatted in JSON or XML.
Unveiling the Key Principles of REST
Uniform Interface: At the core of any REST-based service lies the Uniform Interface, which streamlines and decouples the architecture, allowing each component to evolve independently. This entails the ability to pinpoint individual resources using URIs. Once the client obtains a representation of a resource, it should possess ample information to modify or remove that resource. Additionally, clients shouldn’t assume any actions beyond those specified in the received representation.
Stateless: In a RESTful setup, servers shouldn’t maintain any client state. Requests must be self-descriptive, containing all necessary context for processing. For instance, if a client intends to update a person’s address, it must include the relevant person resource details in the request, based on the representation received from the server earlier. Any state management should reside at the client side.
Client-Server: As previously mentioned, RESTful architecture follows a client-server model, where resource representations flow between the two. Clients interact with RESTful APIs without direct access to resources.
Cacheable: Responses from the server in a RESTful API should be cacheable on the client side, following either implicit, explicit, or negotiable caching mechanisms. Negotiable caching involves agreement between server and client on the duration for which a representation can be cached.
Layered System: This constraint underscores the separation between clients and servers, with multiple layers of software or hardware potentially intervening. Clients operate without knowledge of the specifics of their communication path, enhancing scalability.
Code on Demand (Optional): This optional constraint allows servers to temporarily extend clients by transferring executable logic as representations. It’s the only non-mandatory constraint in the REST architectural style.
A RESTful service needs to adhere to all of the above mentioned constraints (except Code on Demand) to be called as a RESTful API.